
È molto importante conoscere come funziona il file robots.txt perché ti aiuterà a migliorare la SEO del tuo sito.
Questo file è un semplice file di testo che contiene informazioni leggibili dai motori di ricerca, poiché segue una sintassi e delle regole ben precise.

Infatti, è il mezzo utilizzato dai web master per fornire istruzioni ai bot dei motori di ricerca, cioè, i programmi utilizzati per la scansione dei contenuti dei siti web.
Il nome di questi particolari bot è crawler.
Un crawler è un software che analizza le pagine presenti sul web in modo automatico. È in grado di individuare gli URL delle risorse presenti in rete e quindi di accedervi per scansionarne il contenuto.
Grazie alle istruzioni fornite con il file robots.txt, il crawler saprà già quali URL dovrà scansionare e quali invece dovrebbe ignorare. Infatti,
Attraverso le istruzioni contenute in questo file, è possibile inviare istruzioni ai crawler riguardo a cosa devono scansionare e cosa no, cosa deve essere indicizzato e cosa deve rimanere nascosto.
Ne parlo anche nel corso TUTTO SEO, che trovi all’interno della nostra SOS WP Academy, dove spiego poi altre tecniche per comunicare a Google quali sono le pagine importanti del tuo sito web.
Il sistema utilizzato per fornire istruzioni attraverso questo file si chiama Protocollo di Esclusione Robot, in inglese, Robots Exclusion Standard.
Questo significa che esso fornisce principalmente informazioni su ciò che non deve essere scansionato e indicizzato, quindi su ciò che deve essere escluso dalla scansione.
Questo concetto di “esclusione” non deve essere interpretato come un possibile strumento di sicurezza.
Il fatto che il file robots.txt indichi che una certa risorsa o area del sito è esclusa, non significa che essa non sia raggiungibile comunque da parte dei bot.
Il robot, infatti, vede il comando, ma non è obbligato a seguirlo. In pratica, se Google decidesse di visitare comunque le pagine da te escluse, può farlo, così come possono farlo altri tipi di bot ben più malevoli (malware, spambots ecc.).
Quando un bot inizia il processo di scansione di un sito web, il primo URL che visita è www.example.com/robots.txt; qui troverà le istruzioni fornite dal web master.
Come accennato, si può usare il file robots.txt per indicare ai bot di non effettuare la scansione di una o più pagine del proprio sito web.
Questo è particolarmente utile se si hanno, per esempio, contenuti duplicati che potrebbero causare una penalizzazione da parte dei motori di ricerca.
Robots.txt: la struttura del file

La struttura base di questo file è molto semplice.
Ciascuna riga del file è un record, ciascun record è composto da una coppia “campo: valore”.
Possono essere presenti altri dati e simboli.
Il più importante è l’asterisco *, che la funzione di carattere “jolly” e ha il valore di “tutti gli elementi”.
Al contrario dell’asterisco, se il valore viene lasciato vuoto, avrà il significato di “nessun elemento”.
Il simbolo cancelletto #, invece, precede un commento, viene ignorato dai bot ma è utile per inserire informazioni aggiuntive destinate ai programmatori.
Ecco un esempio:
User-agent: * Disallow:
La prima riga serve ad indicare i bot a cui si desidera comunicare le istruzioni (in questo caso, il simbolo * indica “tutti i bot”).
La seconda riga, invece, si riferisce alle pagine o sezioni del sito web che non dovrebbero essere visitate dai bot (nell’esempio, nessuna).
Nel nostro esempio, quindi, non abbiamo nessuna esclusione: tutti i bot devono scansionare tutti i contenuti del sito.
Nelle prossime sezioni, approfondirò l’utilizzo dei vari codici all’interno del file.
Seguendo tutti i passi che ti illustriamo in questa guida, non dovresti incontrare grosse difficoltà.
Ma sappiamo benissimo che, a volte, tutto può succedere!
Niente panico: rivolgiti alla nostra Assistenza WordPress e chiedi il nostro aiuto.
Saremo lieti di offrirti prontamente supporto e assistenza, seguendoti passo per passo verso la soluzione del tuo problema.
Robots.txt: come creare il file
Non tutti i siti hanno un robots.txt: se i bot non trovano alcun file, effettueranno la scansione di tutte le pagine.
Questo accade anche se il file esiste ma non contiene alcun testo. Accedi al tuo sito web tramite FTP oppure con il File Manager del tuo hosting.
Vai nella root, ossia nella cartella principale (solitamente si chiama public_html oppure www) e verifica se il file esiste già.
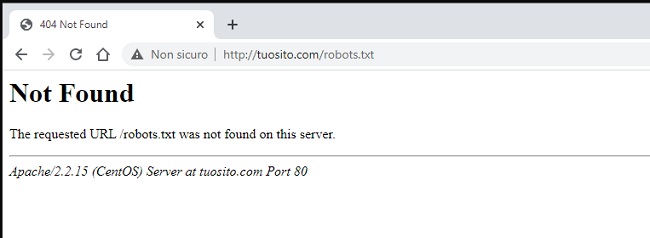
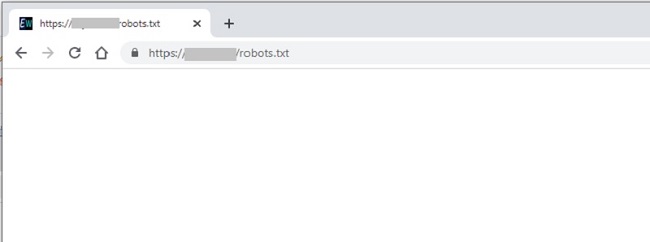
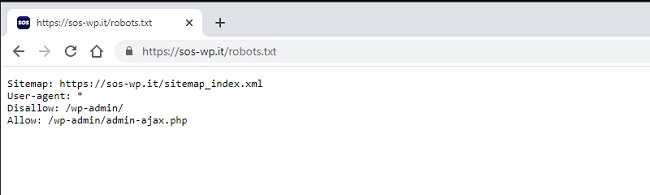
Se non lo trovi, lo dovrai creare tu. Un altro modo per verificare la sua esistenza è digitando sul tuo browser la stringa tuosito.it/robots.txt.
- Se ottieni un errore 404 (pagina non trovata), il file non esiste;

- Se vedi una pagina bianca, il file esiste ma al suo interno non c’è nulla;

- Se vedi una pagina con delle scritte come quelle indicate sopra (User-agent e Disallow), il tuo file esiste e sono presenti delle configurazioni.

Per creare il file robots.txt, devi semplicemente creare un file di testo chiamato esattamente robots.txt.
Usa solo lettere minuscole, non aggiungere alcun carattere o simbolo: il nome del file deve essere precisamente questo, altrimenti i bot non potranno riconoscere il file.
Puoi creare il file sul tuo computer e poi caricarlo via FTP, oppure crearlo direttamente sul file manager.
File robots.txt: come crearlo con Yoast SEO
Se usi Yoast SEO, puoi creare il file con questo strumento.
Vai su SEO > Strumenti e clicca sul link Modifica file.
Seleziona il pulsante Crea file robots.txt e il tuo file sarà creato con già al suo interno le impostazioni predefinite di WordPress.
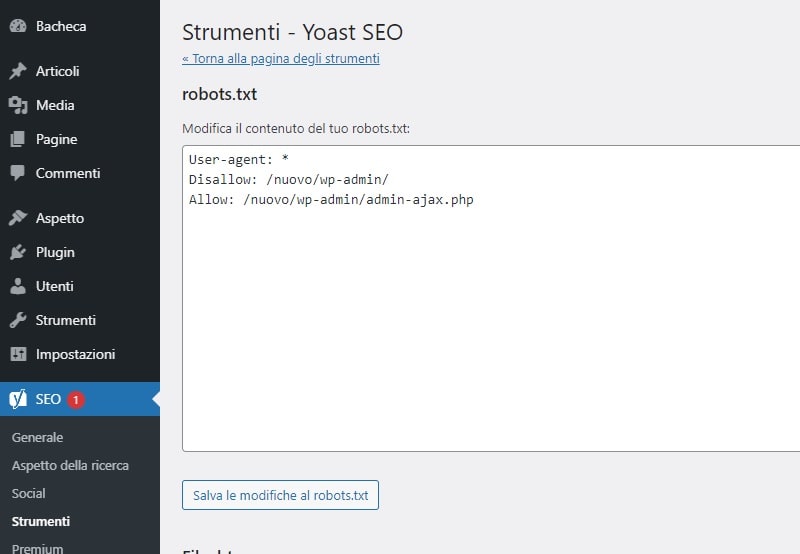
Per esempio, la sezione /wp-admin/ sarà automaticamente esclusa dall’accesso ai robots, dato che si tratta dell’area riservata alla gestione del sito.
Robots.txt con Rank Math
Anche il plugin Rank Math ti permette di generare un file robots.txt direttamente dalla tua Bacheca di WordPress.
Vai su Rank Math > General settings e nella sezione Edit robots.txt vedrai il file generato in automatico dal plugin. Si tratta, però, di un file virtuale. Questo significa che, se hai già un file robots nella tua root, esso non verrà modificato.
I codici da utilizzare
Vediamo, dunque, quali sono i codici che puoi utilizzare all’interno del file robots.txt per fornire istruzioni ai motori di ricerca.
In questa guida indico solo i codici fondamentali; per approfondire l’argomento, visita il sito ufficiale dedicato del Protocollo di Esclusione Robot.
Sitemap

Prima di parlare di inclusione ed esclusione di pagine, vorrei farti presente che il file robots.txt può essere utilizzato anche per indicare ai bot la locazione della sitemap del proprio sito.
Per inserire correttamente le istruzioni ai bot su come trovare la sitemap, dovrai utilizzare questa stringa:
Sitemap: https://example.com/sitemap_location.xml
Inserirai quindi l’URL esatto della tua sitemap. Ricorda di inserire i dati del tuo sito al posto dell’esempio che ti ho mostrato.
User-agent
Passiamo ora alle istruzioni vere e proprie per l’accesso dei crawler ai file del tuo sito. Come abbiamo già visto, il campo user-agent serve ad indicare i bot specifici a cui sono indirizzate le istruzioni.
Un asterisco, come vedi di seguito, è utilizzato per indicare “tutti i robot”:
User-agent: * Disallow:
È però possibile anche indicare i nomi dei singoli user-agent (per esempio, se si vuole limitare l’accesso al bot di un particolare motore di ricerca). Puoi consultare la lista dei nomi dei bot di tutti i motori di ricerca.
Se si desidera creare istruzioni specifiche per diversi user-agent, è possibile farlo in questo modo:
User-agent: nomeuseragent1 Disallow: User-agent: * Disallow: /latuadirectory/
Le prime due righe sono le istruzioni per il determinato user-agent chiamato “nomeuseragent1”, mentre la terza e quarta riga sono le istruzioni per tutti i bot.
Disallow robots.txt

Questa voce introduce la lista di pagine o sezioni che i bot non dovrebbero visitare.
Uno slash indica “tutti i contenuti del sito”.
User-agent: * Disallow: /
Quindi, il codice qui sopra servirà a bloccare tutti i bot da tutto il sito.
Lasciare uno spazio vuoto, come vedi qui sotto, permette invece completo accesso (in quando non viene imposta alcuna restrizione).
User-agent: * Disallow:
Directories
Se vuoi escludere determinate cartelle dalla scansione, inserisci il loro nome dopo la dicitura Disallow, preceduto e seguito da uno slash. Per indicare più cartelle, inserisci un’altra riga di Disallow:
User-agent: * Disallow: /junk/ Disallow: /tmp/
Puoi trovare altre informazioni specifiche sulla sezione sui file robots.txt di Google Webmaster.
Note importanti
I bot possono decidere di ignorare il file robots.txt. Questo avviene più spesso nel caso di bot “maligni” (per esempio, quelli utilizzati per attività di spamming);
Il file robots.txt è pubblicamente accessibile. Fai quindi attenzione a non inserire informazioni riservate.
Da queste due note, puoi facilmente comprendere perché questo file non dovrebbe essere utilizzato per nascondere parti del tuo sito web.
Ad esempio, non utilizzare la stringa Disallow per nascondere una cartella contenente informazioni riservate, perché non avrebbe alcun effetto.
Inoltre, vorrei osservare che ciascun sottodominio deve avere il proprio robots.txt.
Il file presente nella root di miosito.it non può contenere istruzioni relative a blog.miosito.it. Allo stesso modo, il file presente in blog.miosito.it non avrà alcun effetto sugli URL presenti all’interno di miosito.it.
Fai attenzione, infine, ad inserire ogni parametro su una singola riga: ogni riga deve contenere una sola coppia “campo: valore”, altrimenti non verrà interpretata correttamente.
Gli spazi vengono ignorati dai bot, ma possono essere utili per rendere il file più leggibile da parte degli sviluppatori.
Robots.txt e SEO

Vediamo, ora, se il file robots.txt può essere realmente utilizzato ed ottimizzato per la SEO.
Per iniziare, voglio fare un’importante distinzione tra l’attività di scansione (crawling) e quella di indicizzazione (indexing).
Il termine scansione si riferisce all’attività di analisi delle pagine web svolta dai crawler dei motori di ricerca. Questi robottini analizzano contenuti, link, eccetera e riferiscono le informazioni trovate ai server.
Indicizzazione indica, invece, l’inserimento degli URL delle pagine web nell’indice dei motori di ricerca.
Talvolta, anche se i bot dei motori di ricerca “rispettano” l’istruzione di non effettuare la scansione di specifiche pagine web, queste vengono comunque indicizzate.
In questo caso, gli URL delle singole pagine appaiono sulla SERP ma ad essi non viene associata alcuna informazione.
Hai mai letto la frase “Non è disponibile una descrizione per questo risultato a causa del file robots.txt del sito.” nei risultati di ricerca?
Ecco, significa che quella pagina è stata esclusa tramite il file robots.txt.
D’altro lato, è anche possibile che bot ignorino del tutto il file robots.txt.
Suggerisco, quindi, di bloccare i bot dei motori di ricerca utilizzando Meta Noindex.
In questo caso, mi riferisco ai tag meta da posizionare nella sezione “head” della pagina HTML per la quale si vuole restringere l’accesso.
Generalmente, questa soluzione funziona meglio, in quanto previene l’indicizzazione delle pagine.
Seppur utilizzare i tag meta sia preferibile, è da segnalare che anch’essi possono essere ignorati dai bot dei motori di ricerca.
D’altro lato, è importante assicurarsi che non sia bloccato l’accesso a parti del sito che vuoi siano indicizzate dai motori di ricerca.
Robots.txt, che cos’è?
Il file robots.txt è il file utilizzato dai web master per fornire istruzioni ai bot dei motori di ricerca.
Robots.txt com’è strutturato?
Ha una struttura molto semplice composta da almeno due righe di codice. La prima riga serve ad indicare i bot a cui si desidera comunicare le istruzioni (in questo caso, il simbolo * indica “tutti i bot”).
La seconda riga, invece, si riferisce alle pagine o sezioni del sito web che non dovrebbero essere visitate dai bot.
Robots.txt, lo posso creare con Yoast SEO?
Sì, basta andare su SEO > Strumenti e cliccare sul link Modifica file. Selezionare poi il pulsante Crea file robots.txt e il file sarà creato con già al suo interno le impostazioni predefinite di WordPress.
Robots.txt, lo posso mettere Disallow?
Sì, certo. Basta mettere nel file robots.txt il comando Disallow: /
Conclusione
In questa guida introduttiva hai imparato che cos’è e come creare un file robots.txt.
Abbiamo anche visto se è effettivamente utile per la SEO e come si differenzia dal tag Meta NoIndex.
Ti invito infine a leggere la guida ai più comuni problemi dei file robots.txt per evitare qualsiasi intoppo e imprevisto sul tuo sito WordPress.
Il tuo sito ha già questo file?
Quali configurazioni hai utilizzato?
Se hai domande o suggerimenti, condividili nella nostra Community dedicata alla SEO. Troverai esperti del settore con cui confrontarti e chiarire ogni tuo dubbio.







8 Responses
Sempre ottimo, Avevo un problema con un sito e grazie a questa guida sono riuscito a risolvere
Grazie, siamo felici di sapere che il nostro post ti sia stato di aiuto. Continua a seguirci!
Ciao
Grazie per le delucidazioni.
Sto lavorando al mio 2 sito.
Essendo in fase di sviluppo, vorrei che non venisse indicizzato : ad oggi ho modificato il file Robot.txt, seguendo le tue istruzioni, è sulla bacheca di WordPress ho scoraggiato i motori di ricerca, devo fare altro?
Grazie
Ciao Alberto, al momento non devi fare altro, dedicati quindi alla realizzazione del sito. Un saluto!
Marongiu (esclamazione di apprezzamento risalente al liceo), quanto adoro SOS WP; lo dico in generale e non solo per quest’ottimo articolo sulle direttive del file robots.txt.
Grazie Andrea, ti seguo dovunque sia possibile farlo 😉
Grazie! Andrea è contento di saperlo e anche noi del team! A presto.
Ciao, ho un sito gestito con meberpress, per cui è tutto nascosto agl utenti non iscritti. Per evitare scansione e indicizzazione mi consigli di usare un file robots “User-agent: * Disallow: /”? Ho già selezionato “scoraggia i motori di ricerca” nelle impostazione di wordpress.
Grazie
Ciao Lu, dovrebbe bastare il selezionare “scoraggia i motori di ricerca” dalle impostazioni di WordPress. Puoi comunque inserire il codice che indichi nel file robots.txt. Un saluto!